
我目前看了一下,在繁中的部分,好像沒有特別提到Mapping的翻譯,而在簡體的部分則會稱之為映射
的確有時候使用中文去稱呼一些單字可能會導致更混亂,但是我自己覺得有時候寫文章時內容太多中英文參雜時我自己看了也很頭痛XD,所以我在後面的章節盡量會以Mapping來稱呼,但是偶爾還是會使用到映射來稱呼
說了那麼多廢話,到底什麼是Mapping?
資料庫的Schema代表描述表格欄位的格式與記載表格中的關聯,而在ES中Mapping就是說明文檔可能具有的欄位、屬性,每個欄位的類型,例如:text、keyword、date等等,以及底層的Lucene是如何處理這些資料
而Mapping又分成:
| 類型 | 說明 |
|---|---|
| Dynamic mapping | 在dynamic : true或是dynamic : runtime的設定下,當你直接在索引直接添加文檔時,ES會自動幫你把文檔中的欄位設定類型,不需要自己設定 |
| Explicit mapping | 可以自己設定每個欄位的類型 |
Dynamic mapping我們之後再來介紹,這邊先說Explicit mapping
如果是自己要設定的話如下:
PUT /index_name
{
"mappings": {
"properties": {
"欄位名稱(自取)": {
"type": "欄位類型"
},
"另一個欄位名稱" : {
"type": "欄位類型"
}
}
}
}
先呼叫mappings,在裡面包一層properties,接著就是輸入各個欄位,每個欄位內部再包type與實際要儲存的類型
https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-types.html
官方文檔包含了所有的類型的資訊,但是這邊不會一一介紹,只會針對幾個比較常用的講解
接著就讓我們來開始介紹這個欄位的類型:
Keyword type:
"type": "keyword"
一般我們對於一些數字型態的欄位會下意識想使用int之類的方式去儲存,在ES中也有integer跟long等類型。但是除非你需要用到範圍搜尋(range query),不然其實很多數字編號,更常的使用情境是我要找到那一筆id是誰,因此用精確搜尋,有就是用keyword去儲存會更好
Text type:
"type": "text"
至於什麼是analyzer?
分析器(Analyzer):
當text type文檔建立的同時,也會經過分析器然後才儲存進索引中。
而分析器又包含3個部分
題外話,我在這邊找不到不用br html去換行的方式,it邦過濾掉html tag有點痛苦 有知道怎麼在表格內換行的大大可以留言~感謝~
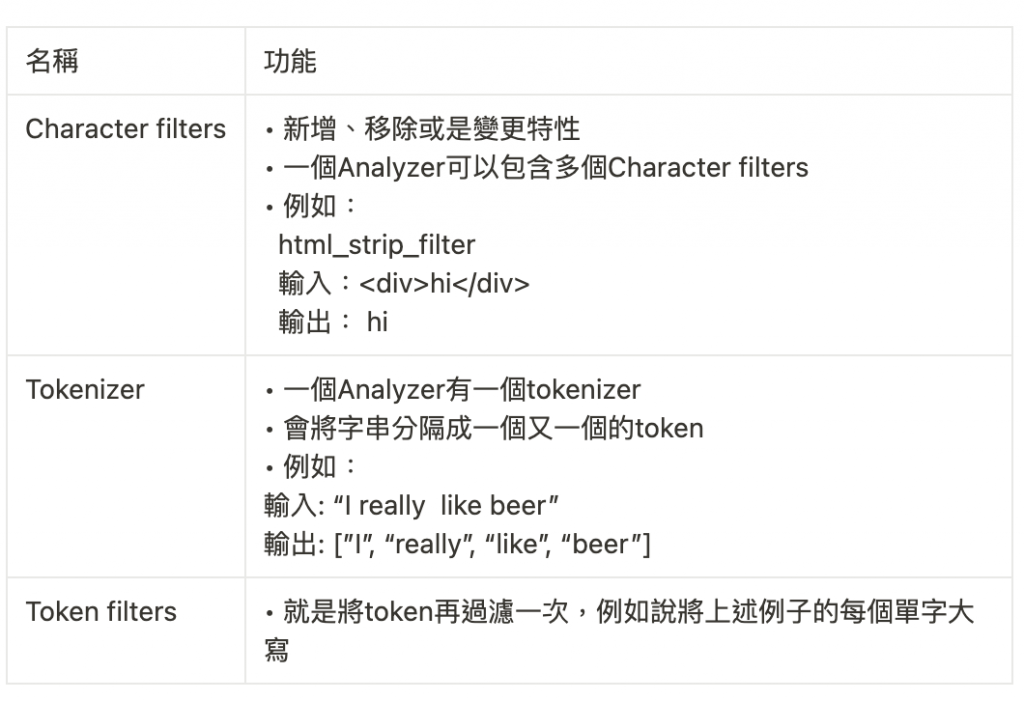
//這邊簡單使用一下Analyzer API
POST /_analyze
{
"text": "He bought lots of food...",
"analyzer": "standard"
}
// result
{
"tokens": [
{
"token": "he",
"start_offset": 0,
"end_offset": 2,
"type": "<ALPHANUM>",
"position": 0
},
{
"token": "bought",
"start_offset": 3,
"end_offset": 9,
"type": "<ALPHANUM>",
"position": 1
},
{
"token": "lots",
"start_offset": 10,
"end_offset": 14,
"type": "<ALPHANUM>",
"position": 2
},
{
"token": "of",
"start_offset": 15,
"end_offset": 17,
"type": "<ALPHANUM>",
"position": 3
},
{
"token": "food",
"start_offset": 18,
"end_offset": 22,
"type": "<ALPHANUM>",
"position": 4
}
]
}
可以看到大寫變成小寫,空格與…經過分析器後都不見了
而這些變化會隨著你使用的Analyzer不同而有所改變
那這邊要帶出今天最重要的概念~Inverted index
剛剛上面提到分割完的這些獨立單字,就會存在Inverted index這樣的數據結構中
反向索引(inverted index):
當然ES對於其他不同資料類型,像是日期與地理資訊就是存在BKD樹結構,不過這不是我們今天的重點~
今天的內容一樣很多:
明天我們會繼續介紹不同類型的mapping~
